


AWS Compute Environment
Recently at my work i had to work on setting up AWS compute environment for one of the batch jobs we are running to process the data from a CSV file stored in an S3 bucket into elastic search. To give a little more detail, we get data from a source upload that data to an S3 bucket. Once the data is uploaded to the S3, we trigger a lambda which in tern submits an AWS Batch job. This is my first blog post ever, i have been procrastinating forever to write a blog post finally i decided to write it, this may not be a perfect blog post but i guess i will improve as i write more.
Setting up Compute Environment for the Batch Job
Here i will only write about setting up the compute environment(all the compute resources like EC2 and etc) for the job to run.
I am assuming that you have all the permissions to create and setup the compute environment. If you want to know more about AWS Batch setup
Let's login into AWS and in the search, search for batch. Once you are on the batch service page you will see something like this.
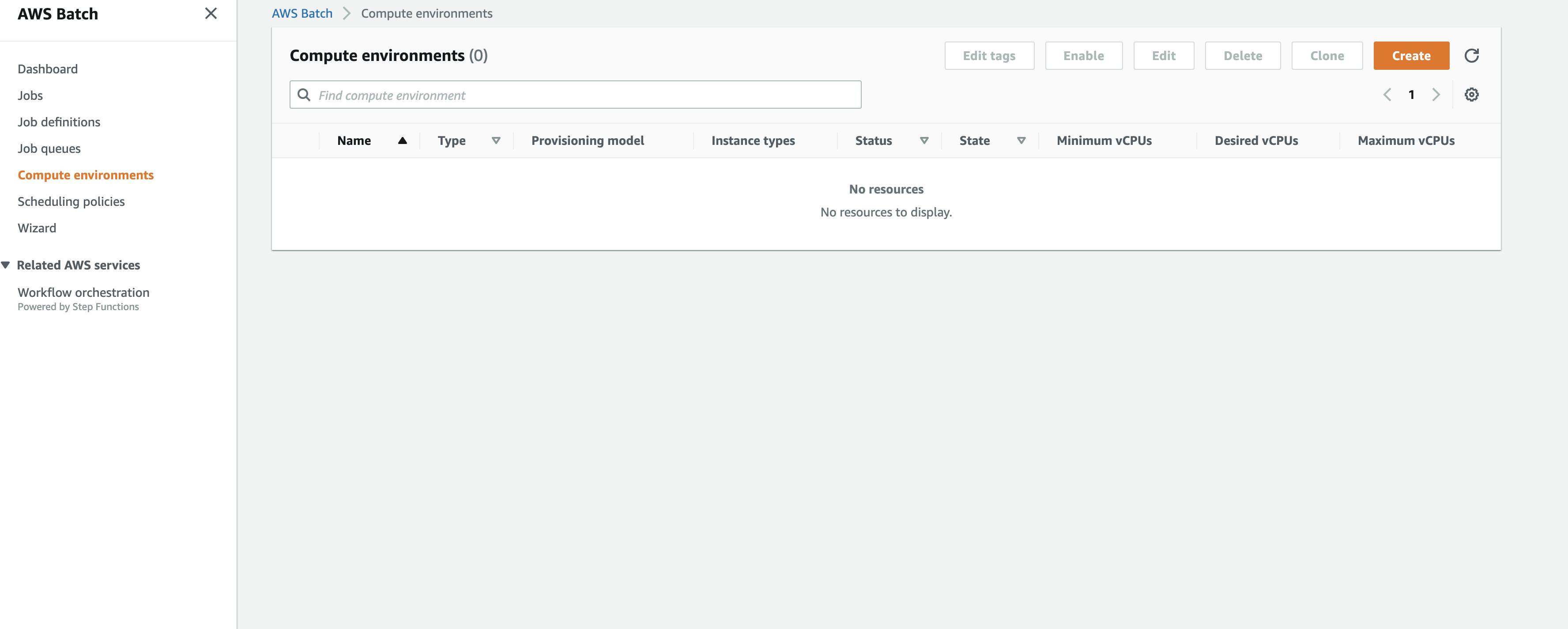
Once on this screen hit create then you will see something like this
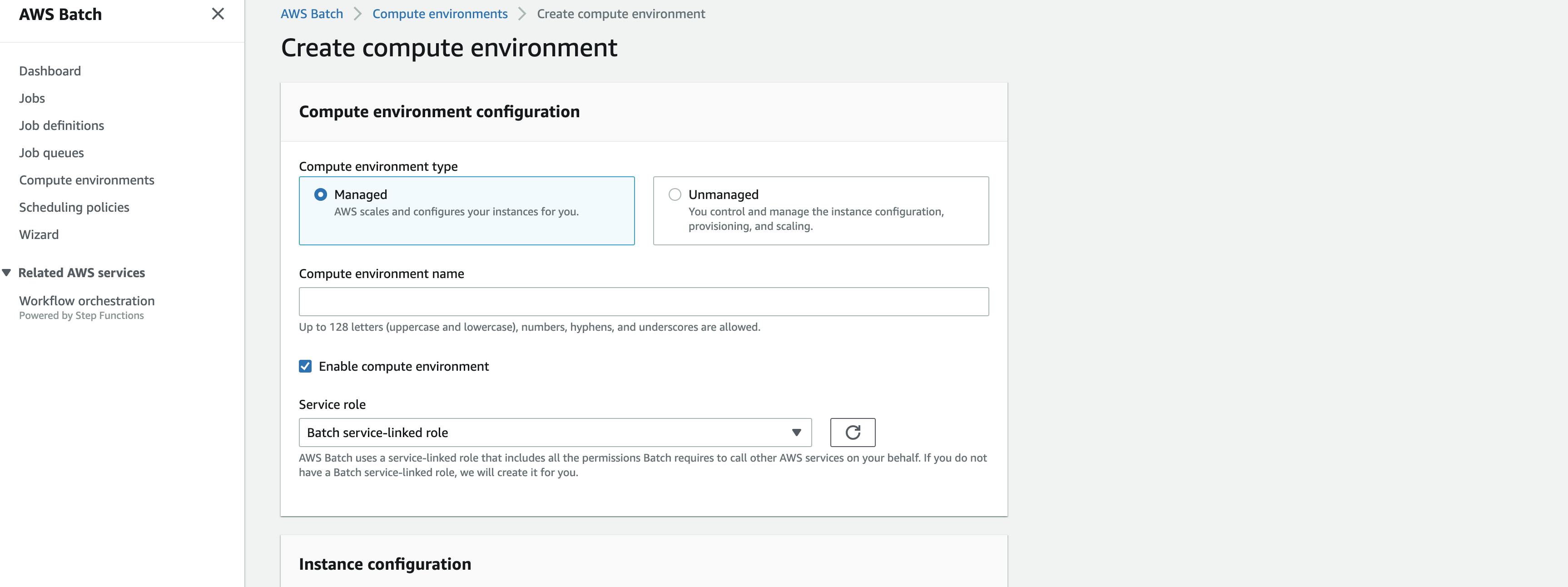
Here you can select managed type or unmanaged, if you are comfortable with managing your own resource capacity go for unmanaged, but i suggest to select managed so that AWS will auto scales the resources based on your job needs.
After that you need a name to your compute environment, this name will be used in creating job queue later, then click on enable the compute environment checkbox, then after that select the service role by default this would be Batch service-linked role, if that is not available you might need to create one.
Now if you scroll a little down you will see something like this
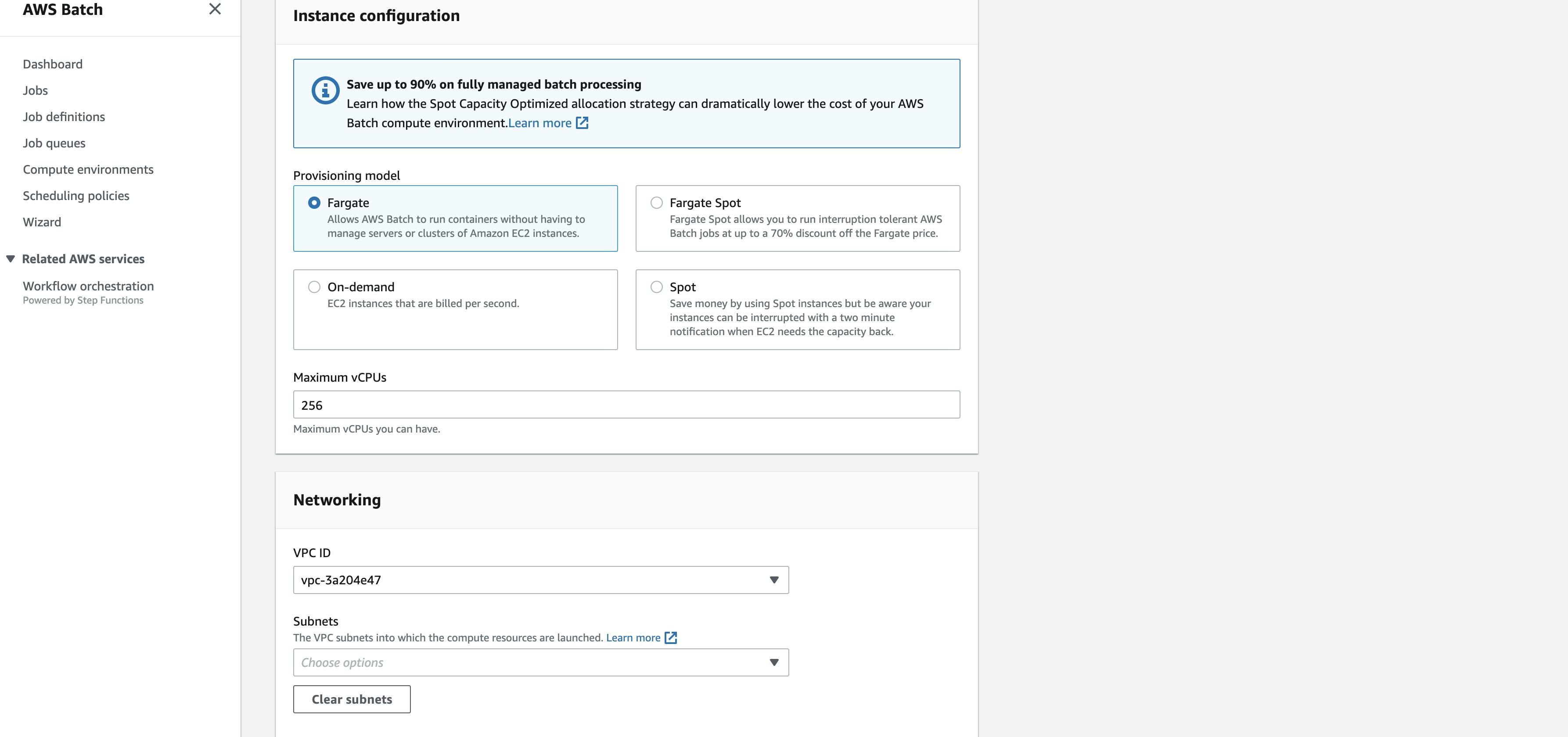 Based on your compute needs select the provisioning model. After that you need to select the number of maximum vCPUs, the VPC and the subnet. Now hit the create compute environment button. You are all set for compute environment.
Based on your compute needs select the provisioning model. After that you need to select the number of maximum vCPUs, the VPC and the subnet. Now hit the create compute environment button. You are all set for compute environment.
Now we can use this compute environment in your job queue. To give a little context on how we submit the batch job. we have a lambda that gets triggered(we can set this trigger like the source data is uploaded to s3 or we can manually trigger the lambda in the console management). This lambda executes and submits the job with all the details(job definition) like job queue and the job queue intern will have the compute environment details.